
[토이 프로젝트] 응답 지연 이슈 : connection-pool-size, index
카테고리: Ayu-coupon
태그: Database
들어가며
쿠폰을 발급하고, 사용할 수 있는 토이 프로젝트를 진행하던 중, 쿠폰 발급 요청에 대한 응답이 매우 느린 것을 확인했습니다.
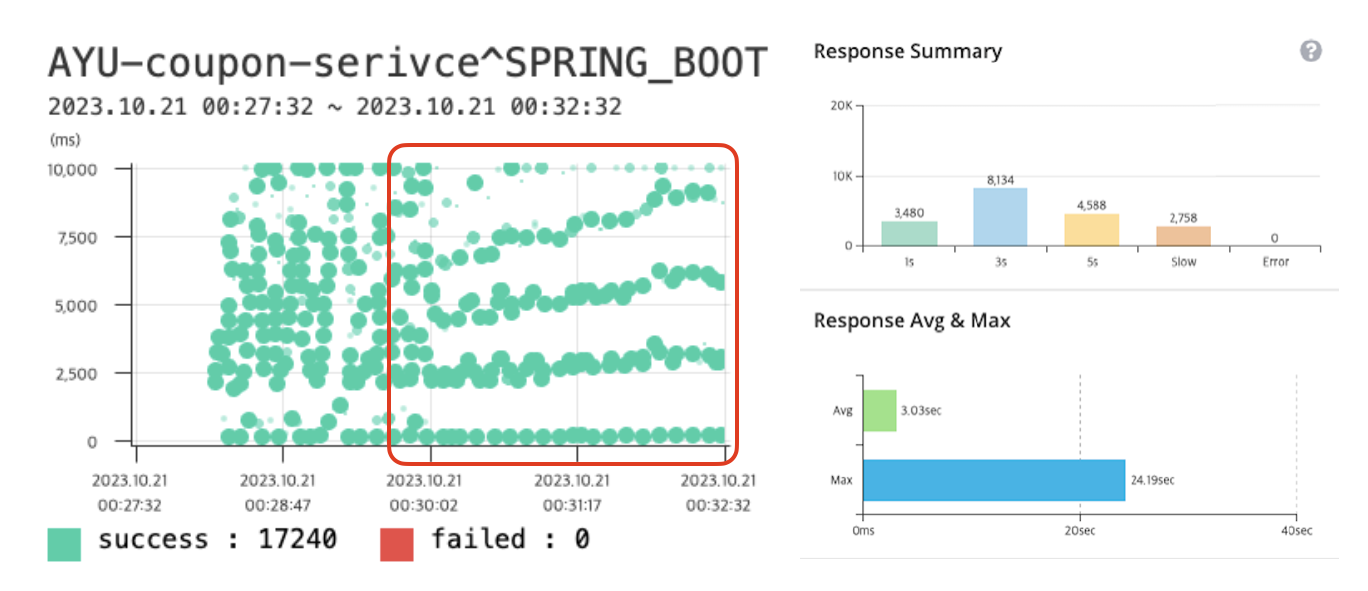
위의 사진을 보면, 요청에 대한 응답 시간이 일정한 간격을 가지고 있는 것을 볼 수 있습니다.
본 포스팅에서는 왜 이러한 형태의 응답 시간을 가지는지 알아보려 합니다.
원인 분석
서버 분석
먼저 원인을 분석하기 위해, 시스템 자원을 확인해보았습니다.
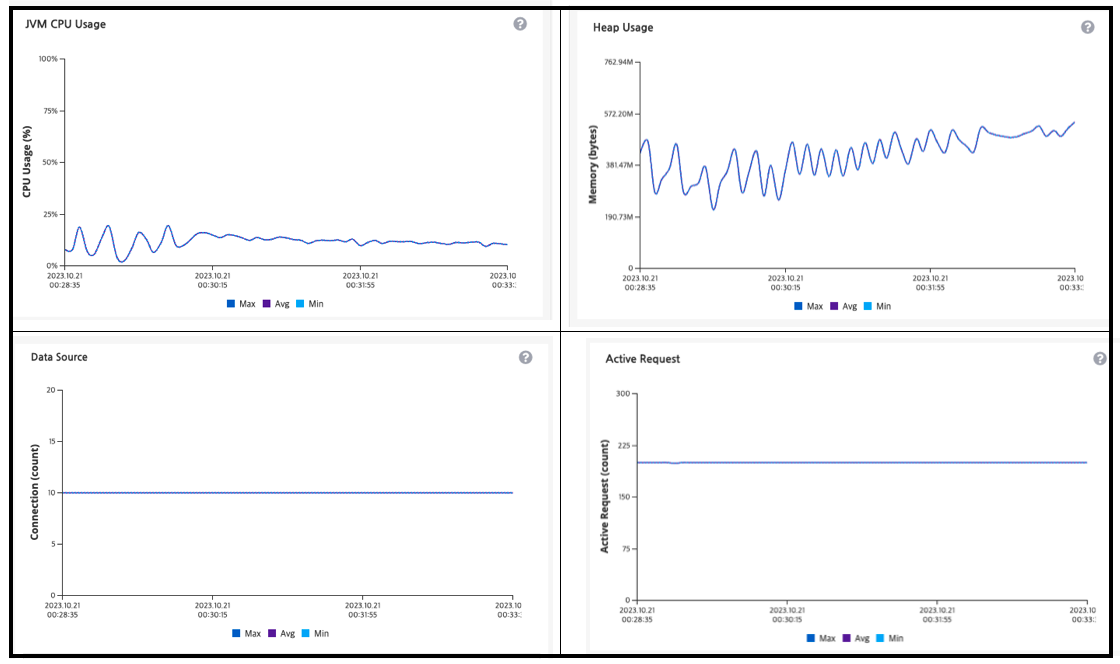
- CPU 사용량은 25%을 넘지 않음
- Heap Memory가 부족한 것처럼 보이지 않음
- Data Source을 전부 사용하고 있음 (Connection pool size = 10)
- Active Request의 수는 200 (Tomcat Thread pool size = 200)
위의 내용을 분석했을 때, Tomcat Thread pool은 고갈되었고, 데이터베이스 커낵션 수가 부족하여 Connection을 얻기 위해 Tomcat Thread는 대기 중이라서 CPU를 효율적으로 사용하지 못하고 있다고 생각해볼 수 있습니다.
Call Tree 분석
실제로 어느 부분에서 병목 현상이 일어나는지 확인해보기 Call Tree도 분석해보았는데요.
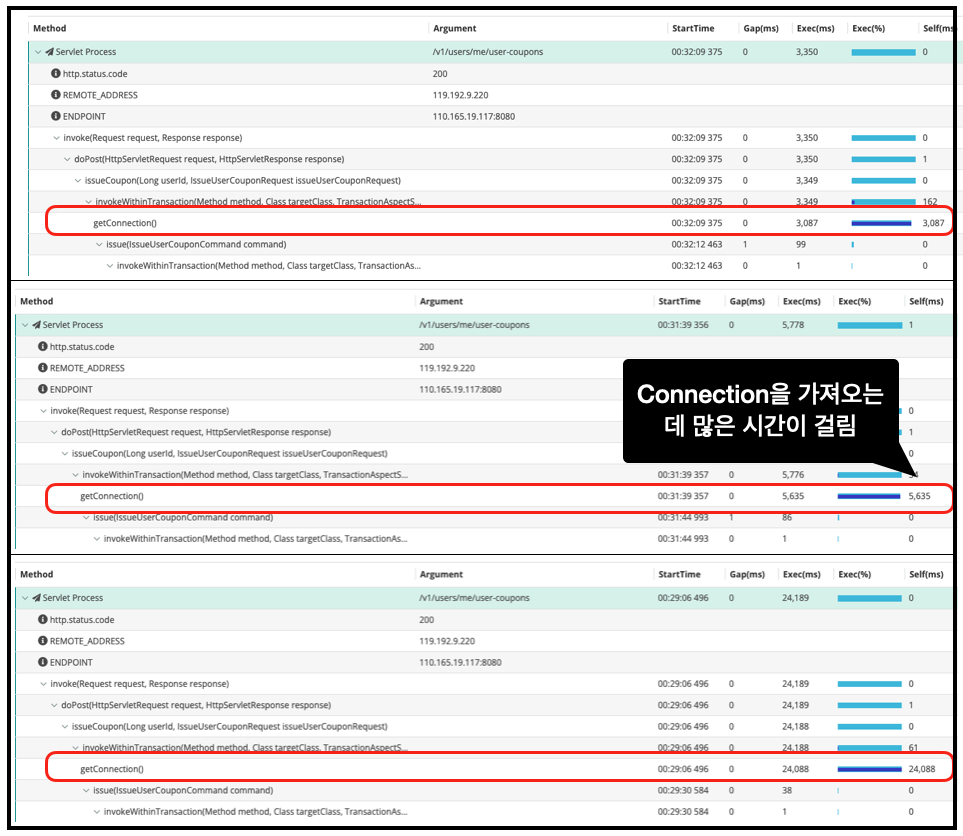
위의 Call tree를 확인해보면 Connection을 가져오는데 많은 시간이 걸렸다는 것을 알 수 있었습니다. Connection 획득하는데에 느린 것은 약 24초가 넘게 걸린 걸리는 것을 확인할 수 있었습니다.
문제 원인 1 : Connection pool size
Connection 획득에 오래걸린다면 Connection pool size를 늘려 문제를 해결할 수도 있지 않을까요?
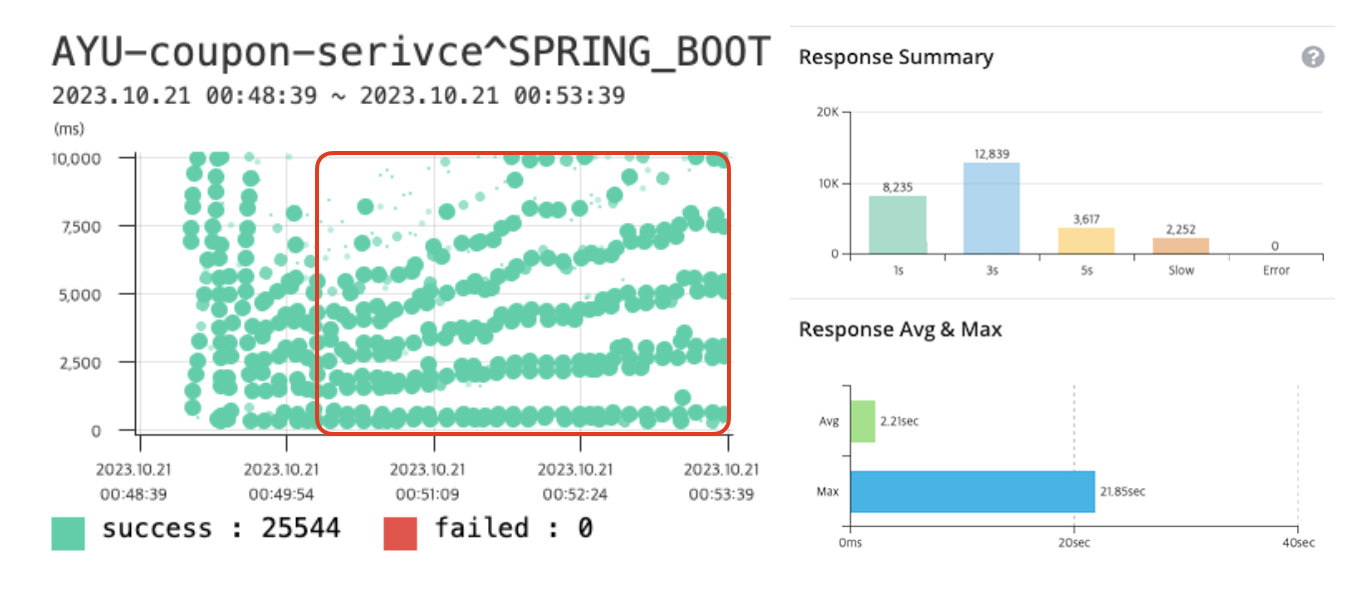
Connection pool size를 40개로 늘리면, 평균 응답시간이 3.03(s)에서 2.21(s)로 줄어들긴 하지만, Connetion을 가져오는데 많은 시간이 걸리는건 달라지지 않았습니다.
오히려 전체 요청에서 Connection 획득 후, 쿼리 응답 시간이 증가한 것을 확인할 수 있습니다.
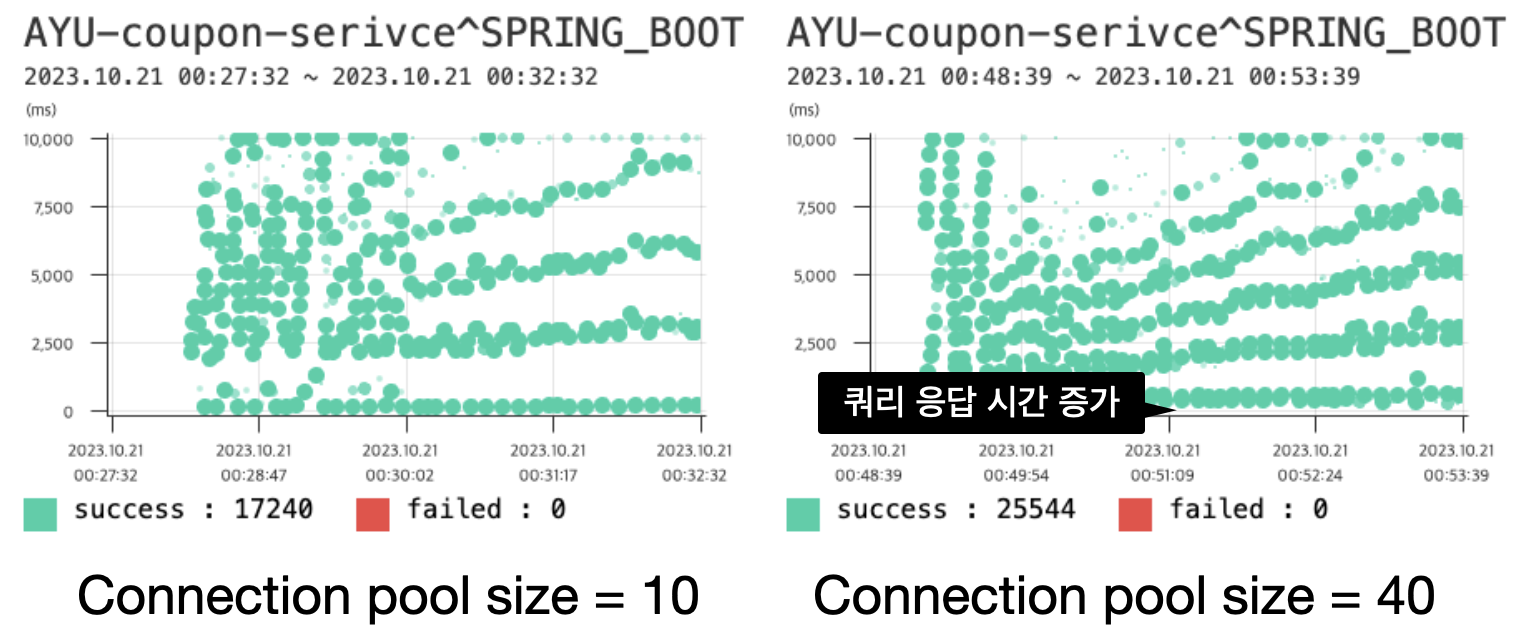
Connection 획득에 오랜 시간이 걸린다. 라는 문제를 해결하기 위해서는, 왜 오래걸리는지 생각해야할 필요성이 있습니다.
Connection pool
Connection pool은 DB와 미리 connection(연결)을 해놓은 객체들을 pool에 저장해두었다가. 클라이언트 요청이 오면 Connection을 빌려주고, 처리가 끝나면 다시 Connection을 반납받아 pool에 저장하는 방식입니다. 이 말은 클라이언트 요청을 끝내지 못하면, Connectoin을 반납하지 않는다는 말인데요.
실제로 아래의 사진처럼 하나의 요청에 대해 많은 시간이 걸리는 것을 확인할 수 있습니다.
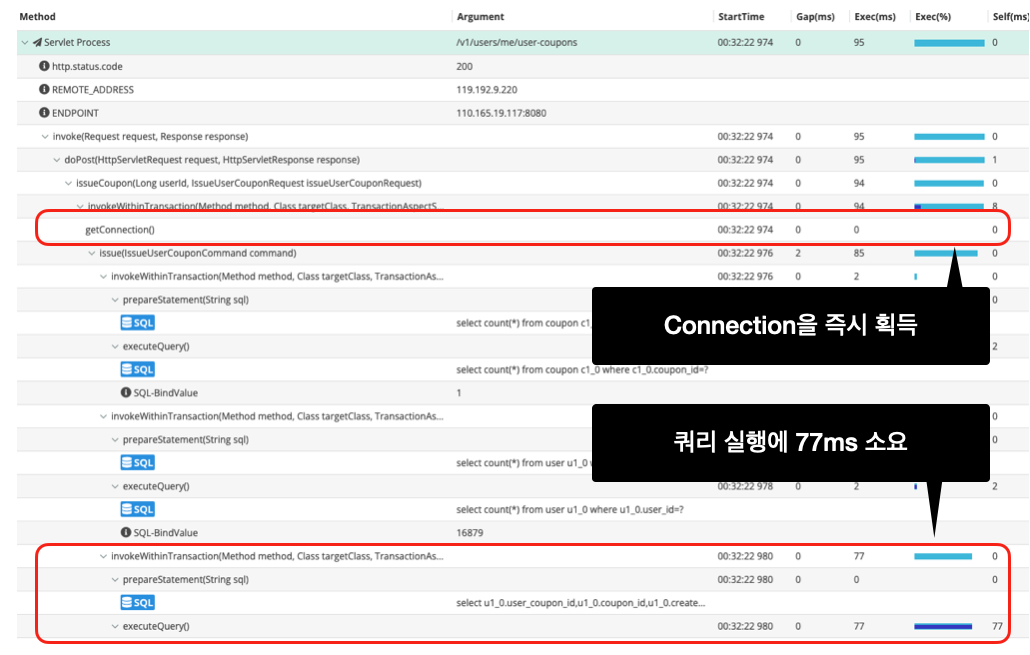
위의 사진은 클라이언트 요청에 대해 connection을 바로 획득했지만, 요청 처리를 위한 쿼리에 대해 77(ms) 라는 시간이 소요되었습니다.
위의 쿼리는 무엇이길레 저렇게 느린걸까요? 아래는 문제의 쿼리입니다.
select
u1_0.user_coupon_id,
(생략)
from
user_coupon u1_0
where
u1_0.user_id = '?'
77(ms)라는 시간을 소비한 쿼리치고는 너무나도 단순한 조회 쿼리입니다. 심지어 데이터 건수는 고작 10만개입니다.
Full scan과 Index scan
데이터베이스가 데이터를 찾는 방식은 여러가지가 있고, 그 중 Full scan과 Index scan 방식이 있습니다.
Full scan은 테이블에 존재하는 모든 데이터를 읽어 가면서 조건에 맞으면 결과로서 추출하고 조건에 맞지 않으면 버리는 방식입니다. 결과를 찾기 위해 데이터가 저장된 모든 블록을 읽은 방식입니다.
그에 반해 Index scan은 Index를 사용하여 테이블에서 원하는 데이터를 빠르게 찾을 수 있습니다. 자세한 내용은 향로님의 블로그를 참고해주세요.
문제의 원인 2 : 느린 쿼리 응답 속도
단순한 조회 쿼리의 성능이 낮은 이유는 바로 Full scan을 하여, 데이터를 조회했기 때문인데요. mysql explain 명령어를 통해 실제로 Full scan했다는 것을 확인할 수 있습니다.
mysql> explain
-> select
-> u1_0.user_coupon_id,
-> u1_0.coupon_id,
-> u1_0.created_at,
-> u1_0.expired_at,
-> u1_0.issued_at,
-> u1_0.status,
-> u1_0.updated_at,
-> u1_0.used_at,
-> u1_0.user_id
-> from
-> user_coupon u1_0
-> where
-> u1_0.user_id = '9999';
| (full scan)
V
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | all | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | u1_0 | NULL | all | user_id_idx | user_id_idx | 8 | const | 1 | 100.00 | Using index condition |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-----------------------+
Full scan가 사용된 이유
Full scan이 사용되는 경우는 다음과 같습니다.
- 적용 가능한 인덱스가 없는 경우 <- 현재 조회 쿼리가 Full scan된 이유
- 넓은 범위의 데이터 엑세스
- 소량의 테이블 엑세스
- 병렬처리 엑세스
- FULL 힌트를 적용한 경우
문제의 원인이 되는 쿼리는 바로 Index를 적용하지 않고 where 절을 사용했기 때문에, 적용 가능한 인덱스가 없어 Full scan을 통해 데이터를 조회한 것이었습니다.
(조회 테이블의 PK는 user_coupon_id이고, where절에 사용된 컬럼은 user_id입니다.)
Connecion pool size를 늘리고 인덱스를 사용한다면?
아래와 같이 애플리케이션 환경을 변경 후 테스트를 진행해보았습니다.
- where절에 사용되는 컬럼을 테이블의 인덱스에 추가
- Connect pool size 40으로 증가

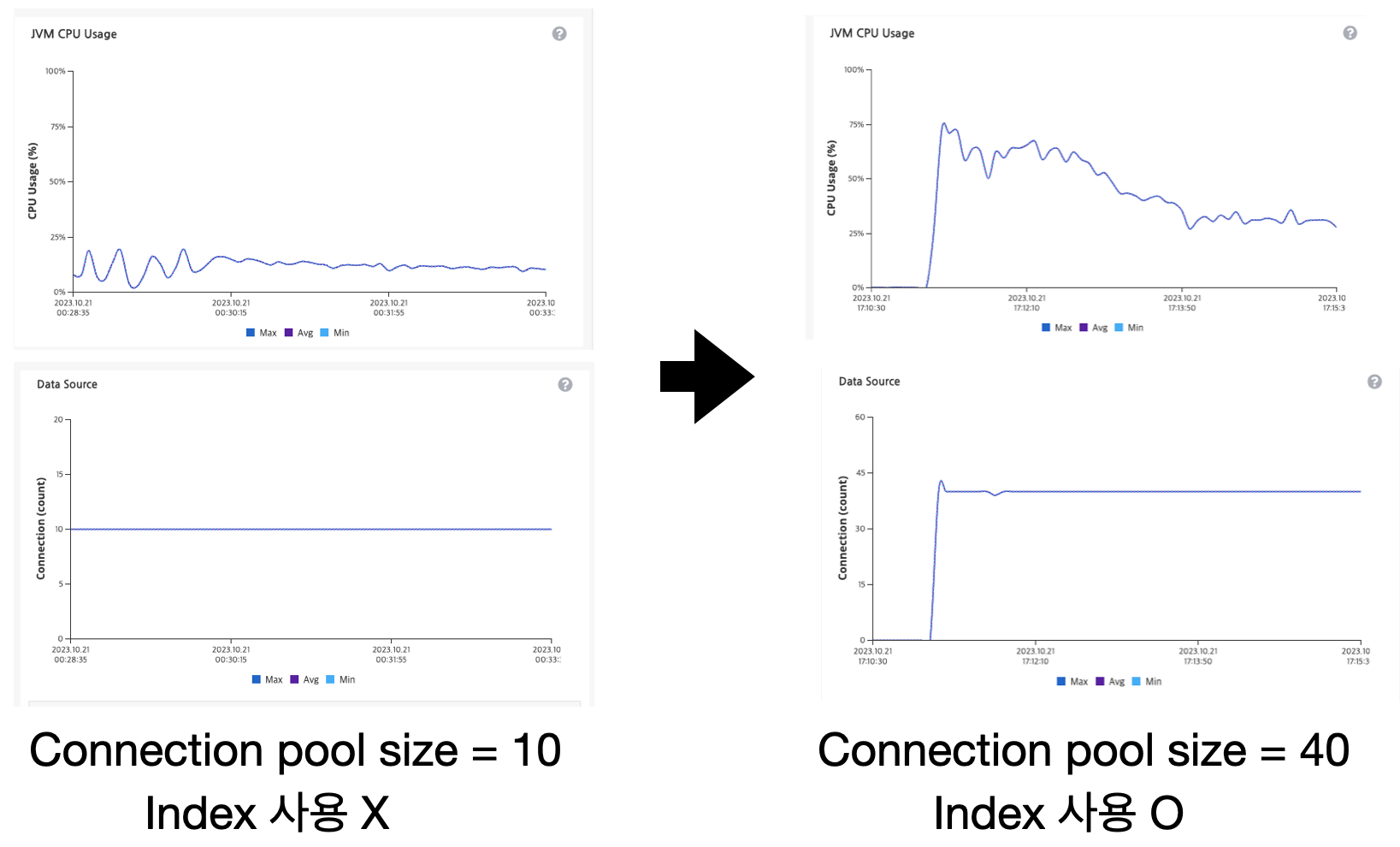
- 응답 시간 3.03(s) -> 1.17(s)로 감소
- JVM CPU 평균 사용량 약 10.8% -> 약 32.1%로 증가
위의 결과를 봤을 때, Connection 획득 대기 시간이 줄어들었기 때문에 더 효율적으로 CPU 사용하는 것을 볼 수 있습니다. 하지만 여전히 CPU 사용률이 높아 보이지는 않습니다.
환경에 따른 테스트 결과
| Index 사용 | Connection pool size | CPU 사용률(서버 가동 후 2분 후 평균) | TPS |
|---|---|---|---|
| X | 10 | 10.8% | 61.2 |
| X | 40 | 12.1% | 69.1 |
| O | 10 | 17.9% | 110.1 |
| O | 40 | 32.1% | 175.2 |
| O | 100 | 35.7% | 179.3 |
정리
Connection pool size를 늘려 충분한 Connection 수를 확보했고, 인덱스를 사용하여 조회 성능을 향상시켜 빠르게 Connection을 반납하도록 하여 서버의 퍼포먼스를 향상시켰습니다.
하지만 아직 CPU의 사용률을 보면, 개선의 여지가 남아있다는 것을 알 수 있습니다.
추가 이슈
Connection pool size를 늘리고, 인덱스를 사용하여 조회 성능을 높여 애플리케이션 서버의 퍼포먼스를 증가시켰습니다.
하지만 반대로 Connection pool size를 늘리면 늘릴수록, Lock을 사용하는 조회 쿼리의 성능은 낮아졌습니다.
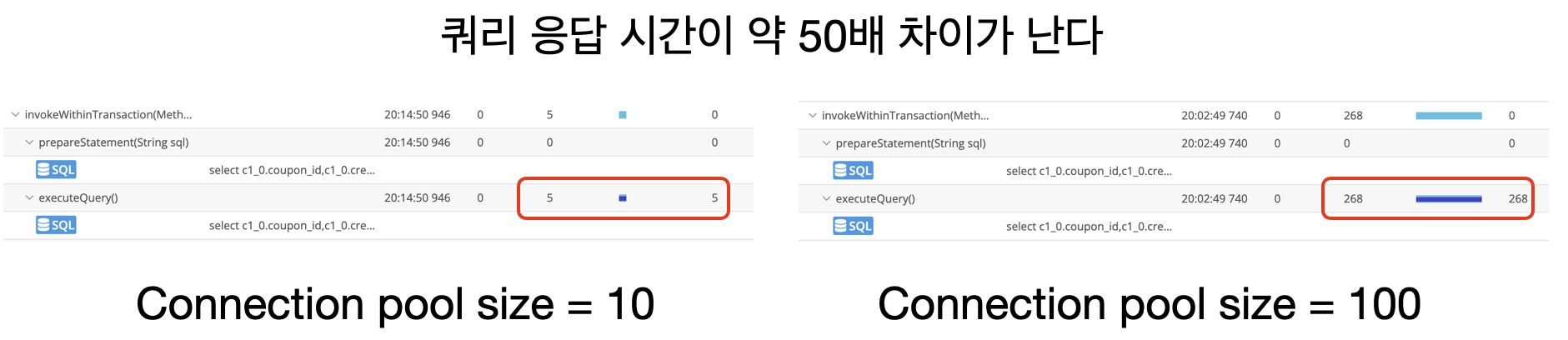
-- Lock을 사용하는 조회 쿼리
select
c1_0.coupon_id,
(생략)
from
coupon c1_0
where
c1_0.coupon_id = ? for
update -- 명시적 Lock
그 이유로는 DB에 연결된 Connection이 많아졌기 때문입니다.
즉, Lock에 의해 잠긴 테이블에 접근하려는 Transactoin의 대기 시간이 늘어났고, DB 서버에서 동작하는 쓰레드가 늘어났기 때문에 쓰레드 컨텍스트 스위칭으로 인한 오버 헤드가 증가했다고 생각하고 있습니다.
다음 포스팅은 위의 이슈를 해결하는 글을 작성하려 합니다.
끝까지 봐주셔서 감사합니다!
댓글 남기기